
皆さんこんにちは!Yuiです!
2月8日対話型AI「Bard」の名称を「Gemini」に変更することが決まりました。
現在はGemini Proと呼ばれる中間レベルのモデルを搭載しており、より高度な性能を持つようになりました。
- Geminiについて詳しく知りたい。
- 他のサイトも見たけど難しくて理解できない。
という方に向けて記事を書いていきます。AIのトピックは複雑で理解するのが難しいです。なので僕なりに噛み砕いて解説していきます。
- Geminiについて詳しく知ることができる。
- AIに関する知識をつけることができる。
AIの時代が来ています。AIが普及することの問題も多く取り上げられていますが、AIを使いこなせるか否かで人類に大きく差が開くと言われています。なのでAIを知る必要があると考えます。
- Geminiとは何か
- Geminiの特徴
- GPTとの違い
- DeepMindについて
- まとめ
について書いていきます。難しい内容であるトピックですが初心者向けに解説していきます。では1つずつ見ていきましょう。

Geminiとは
- DeepMind社(Google)が開発
- 2023年12.6日にリリース(この時点では未完成)
- Geminiの意味は双子
2023年12月6日にリリースしていますが、初めてGeminiの存在を発表したのは2023年5月11日です。そこではGoogle I/Oが発表しました。
12月6日にリリースと言えど、当時は開発途中だったそうです。「こんなふうに持っていきたい。」というコンセプトを発表している印象です。
Geminiの意味は双子座です。なぜ双子座なのかは分かりませんが、なんらかの意味を込めて名付けたのではないかと考えます。
特徴
Geminiの特徴について解説していきます。
- Googleが開発した次世代AIモデル
- マルチモーダルAI
- GPT-4を凌駕する性能
- 「Nano」「Pro」「Ultra」の3モデルを展開
Googleが開発した次世代AIモデル
AIモデルとは人工知能そのものについて指すと思ってくれればOKです。
入力→AIモデル→出力の順番で特定の目的を処理します。
どんな情報も処理できるものにAGI(Artificial General Intelligence)というものがありますが、GeminiはAGIではありません。AGIはまだ、開発段階にあり、Geminiはまだそのレベルに達していません。
とはいえGeminiはGoogleが発表した凄いAIであることに変わりません。
マルチモーダルAI

普通のAI:入力→出力(それぞれ1つずつしか受け付けない。)
マルチモーダルAI:入力→出力(2種類以上受け付けられる)
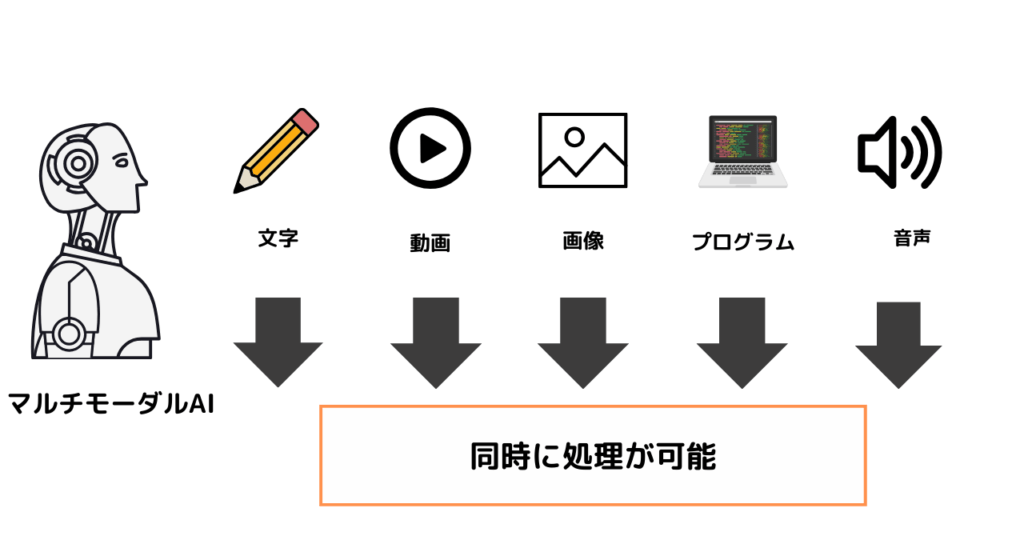
マルチモーダルAIとは文字/画像/動画/音声/プログラムなどの異なる種類の情報を同時に処理し、理解できる人工知能のことです。人間が五感を持って情報を処理するように、マルチモーダルAIも複数の異なる情報を組み合わせてより、高度な理解と判断か可能となりました。
GTP-4VもマルチモーダルAIとなっています。公式によると”anything to anyithing”(何から何まで受付可能)と謳っています。自信にあふれていますよね。
GPT-4を凌駕する性能
MMLU(大規模マルチタスク言語理解テスト)というテストがあります。これは、数学、物理学、医学、生物学、倫理など57科目の知識と問題解決処理能力を評価するためのテスト自然言語のAIのベンチマークによく用いられます。
各分野の人間の専門家が実際に回答すると正答率は89.8%なのに対しGeminiは90.0%です。ちなみにGPT-4(SOTAモデル)は86.4%です。
SOTAモデルというのはStete-of-the-artの略で「最先端」という意味があります。つまりGPT-4は現時点で最高のAIということです。しかし、今回解説しているGeminiが超してまったということです。
引用:https://deepmind.google/technologies/gemini/#capabilities
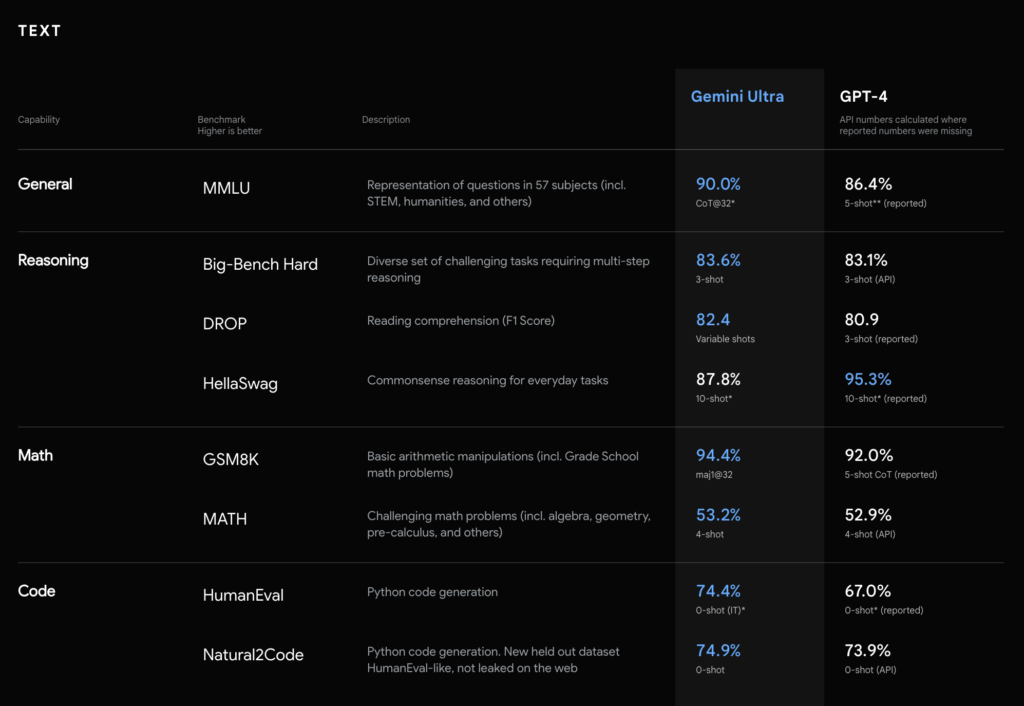
MMLU以外の言語処理テストもありますが、GeminiがGPT-4Vを上回っているテストが多く見られます。
人間の専門家のレベルを超えたのはAIモデルでは世界初だそうです。
「Nano」「Pro」「Ultra」の3サイズを提供
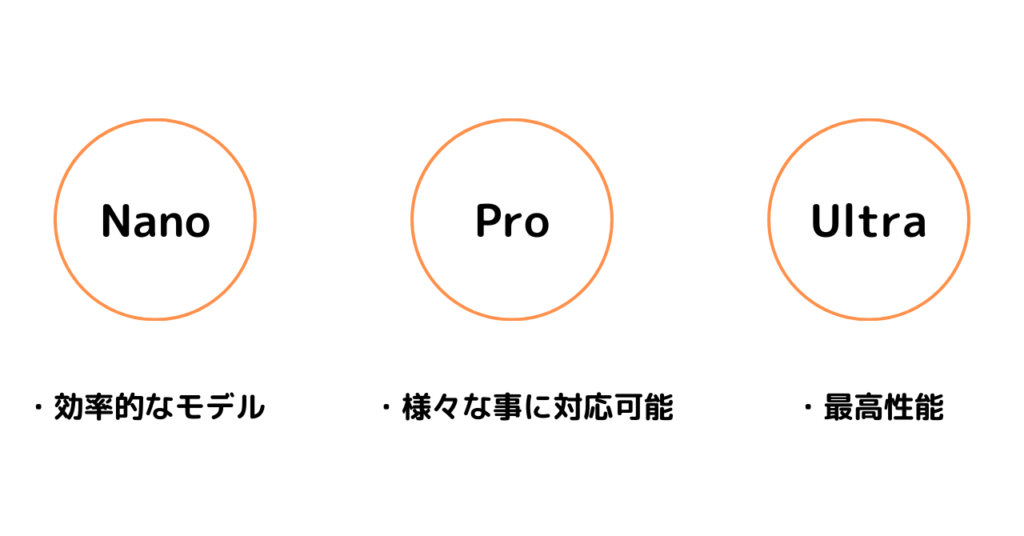
Geminiは3サイズを提供しています。
- Nano→「オン-デバイス-AI」として利用されている効率的なモデル。
- Pro→汎用的で様々なものに対応できる万能モデル
- Ultra→非常に複雑なタスクもこなせる最高性能なモデル
Nanoは軽量で高速なモデルです。スマホなど低スペックな環境で使用するのに適しています
オンデバイスAIとは、スマホなどの中にAIを組み込みローカルで処理を行う技術です。従来のクラウド型より高速で、オフラインでも使うことができプライバシーも保護されます。
ネット環境がなくても使用できるのは凄いですね。僕たちの日常の困ったことをサポートしてくれそうです。
Proは中程度の規模と性能を持つモデルです。バランスが取れており、様々なタスクに対応することができます。Ultraより処理速度は速いですが、能力は劣ります。汎用モデルとは言えども凄い性能を持つAIになります。
Ultraは最も大規模で能力の高いモデルです。高度のタスクや、大量のデータを扱う必要がある場合に適しています。そしてGTP-4を超える過去最高のAIになります。
Gemini Ultraはまだリリースはされていません。2023年12月6日での発表によると2024初頭という表現がされています。2月、遅くても3月にはリリースされるのではと予想します。どのサービスも初めは英語版からのスタートなのでおそらくこのGemini Ultraも英語版からリリースされ順次日本語にも対応していくと思います。
GPTとの違い
- DeepMind(Google)が開発
- Bardで無料利用可能
- 上位モデルはBard Advanced
- Nanoならデバイスに搭載可能
- マルチモーダルAI前提でゼロから設計・開発された
発表はGoogleがしましたが、開発はDeepMindが行いました。
元々のBardの名称がGeminiに変更し、Bardのページで使用可能です。Geminiは以前PaLM2が裏で動いていましたが、Gemini Proが日本語に対応したので今は、Geminiの裏ではProが動いています。
上位モデルはBard AdvanceというものでそこでUltraを使用できるようになります。上でも解説した通りまだUltraはリリースはされていません。
Nanoは「Google Pixel 8 Pro」に搭載されています。ですが、英語版のみです。そのうち日本語も対応されると見ています。
Geminiはマルチモーダルで使うこと前提で設計されています。これがGPTとの大きな違いですね。
Nanoはコンパクトモデルとは言われていますが、Google Pixel 8 Proの価格は非常に高いですね。
- OpenAIが開発
- chatGPTで利用可能
- 上位モデルはchat GPT Plus
chat GPTはOpenAIという非営利の研究会社によって開発されました。OpenAIはイーロン・マスク、サム・サルトマン、イリヤ・サツケヴァーさんなどによって2015年に設立されました。
chatGPTではGPT-3.5が無料で使用可能となっています。
上位モデルであるchatGPT Plusは月額20ドルで利用できます。課金することによってGPT-4が使用可能になります。3.5より4の方が性能がいいです。
Deep Mindについて
DeepMindは、イギリスのロンドンい本社を置く人工知能(AI)研究会社です。2010年に設立され、2014年にGoogleに買収されました。
主な成果
- 囲碁や将棋などのゲームで世界チャンピオンに勝利したAIプログラムを開発。
- AlphaFoldと呼ばれる音声合成システムを開発。
- WaveNetと呼ばれる音声合成システムを開発。
- Gatoとと呼ばれるマルチモーダル・マルチタスクAIを開発。
まとめ
- 「Gemini」はGoogleが発表した次世代AIモデル。
- 開発したのは「AlphaGo」で有名なDeepMind。
- テキスト/画像/動画/音声などにAIモデル単独で対応するようにゼロから構築された「マルチモーダルAI」。
- GeminiはGPT-4を上回る事もある。
- AIのテスト(MMLU)で人間の専門家を上回る性能・評価を叩き出した世界初のAIモデル。
- すでにサービス開始。(Ultraはまだ。)
この記事ではこれらのことを解説していきました。冒頭でも述べた通り、AIが凄まじい速度で進化を遂げています。学校やニュースでは、「chat-GPTで宿題を済ませてしまう。」として問題視されています。
ですが、このようなAIを使えるか否かで大きな格差が開くことになると僕は考えています。
なので、このような最先端の情報を常にインプットし続けて時代の流れに沿っていく必要があると考えます。


コメント